การออกแบบระบบให้รับ Request เยอะๆ

เมื่อเดือนที่แล้ว มีโอกาสกลับไปเป็น Guest Speaker ที่ภาค ในวิชา System Analysis and Design
อาจารย์ให้อิสระในเรื่องของหัวข้อ เลยตัดสินใจว่าอยากเล่าเรื่องที่มันสนุกๆ เผื่อน้องๆจะสนใจสาย Technical กันมากขึ้น หลังจากคิดอยู่หลายวัน ก็มาจบลงที่เรื่องนี้
ด้วยเวลาที่จำกัด รู้สึกว่าถ่ายทอดเนื้อหาได้ไม่ครบเท่าที่ควร เลยเอาเนื้อหามาเขียนเป็นบทความซะเลย จะได้ไม่ค้างคาใจ
เราจะเริ่มตั้งแต่การรับ Requirement การกะปริมาณ Load ของระบบ ไล่ไปจนถึงเทคนิคเบื้องที่ใช้ในการออกแบบให้รับ Request ได้เยอะขึ้น และสามารถโตตามปริมาณคนใช้ในอนาคตได้
ระบบลงทะเบียนเรียน
เพื่อให้ง่ายต่อการอธิบาย เราจะใช้ระบบลงทะเบียนเรียนของมหาวิทยาลัยเป็นตัวอย่าง เรื่องมีอยู่ว่า
ทุกๆเทอมมหาวิทยาลัยจะเปิดให้นิสิตลงทะเบียนเรียน"พร้อมกัน" ผ่านทางเว็บไซต์
ก่อนการลงทะเบียนเรียน แต่ละคณะและภาควิชา จะส่งรหัสวิชา, ชื่อวิชา, และจำนวนนักเรียนที่รับได้ในรายวิชานั้นๆ ข้อมูลเหล่านี้จะถูกบันทึกลงในฐานข้อมูลพร้อมแล้ว
ปัญหาหลักของระบบปัจจุบันคือ เมื่อถึงเวลาเปิดให้ลงทะเบียน เว็บจะล่มเป็นประจำ เพราะการลงทะเบียนเป็นแบบ First-come, first-serve ใครลงได้สำเร็จก่อนภายในจำนวนที่รับได้ในวิชานั้นๆก็จะได้เรียน ส่วนคนที่ลงไม่ทันก็อด ผู้ใช้จึงจะนั่ง Refresh หน้าเพจรอก่อนเวลาเปิดลงทะเบียน และแข่งกันลงทะเบียนให้ได้เร็วที่สุด
ทางฝ่ายทะเบียนจึงอยากให้เรามาช่วยออกแบบระบบให้ใหม่ เพื่อแก้ปัญหาเรื่องนี้
จริงๆแล้วตัวระบบลงทะเบียนจริงไม่ได้มีฟังก์ชั่นแค่การลงทะเบียนเรียนอย่างเดียว และความซับซ้อนค่อนข้างเยอะ ในบทความนี้เราจะคิดง่ายๆว่าระบบนี้เอาไว้ใช้ลงทะเบียนเรียนอย่างเดียวพอ
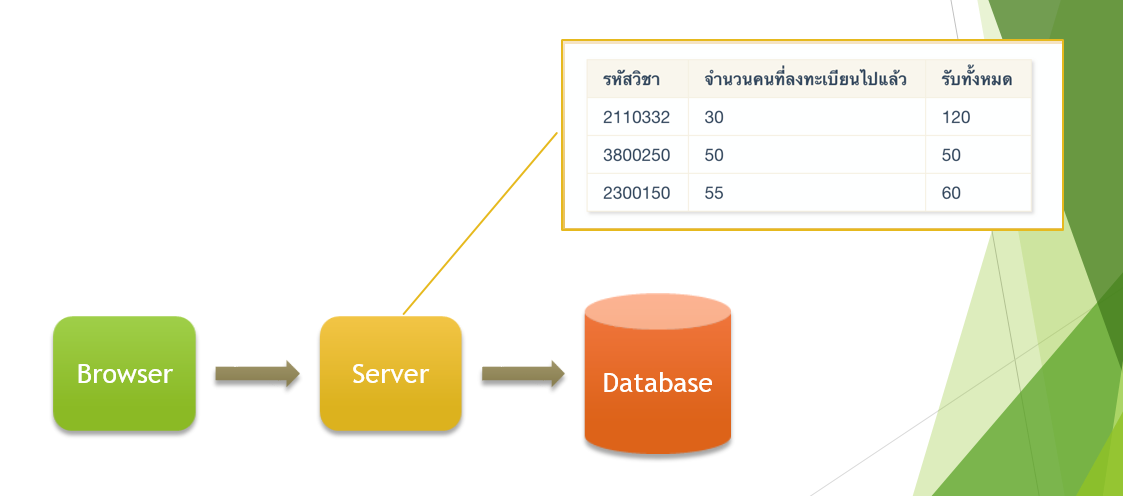
ก่อนจะไปถึงเทคนิค เรามาเริ่มต้นด้วยสถาปัตยกรรมปัจจุบันของระบบ ที่เป็น 3-Tier Architecture คือแยก Server ออกมาไว้รับ Request และแยก Database ออกมาเพื่อทำ ตามรูปข้างล่าง
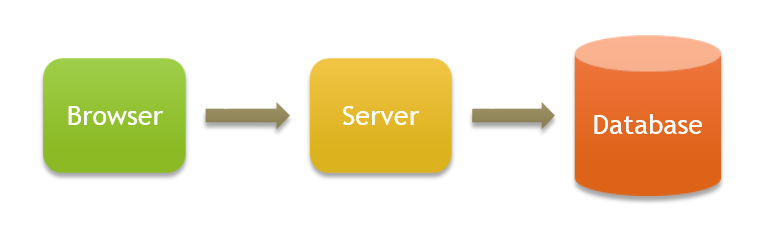
เพื่อความเรียบง่าย ผมจะถือว่าฝั่ง Server เป็น Stateless นะครับ คือไม่มีการเก็บข้อมูลใดๆอยู่ในนั้น ทุกอย่างลง Database หมด
จากนั้นเราจะทำการ Sizing คือการประเมิน Workload ของระบบแบบคร่าวๆ ข้อมูลสำคัญ 3 อย่างที่เราควรรู้คือ
- ที่จังหวะ Peak Load (ช่วงที่แย่งกันลงทะเบียนเรียน) จะมีผู้ใช้ทั้งหมดประมาณกี่คน
- ผู้ใช้แต่ละคนจะส่ง Request เท่าไร
- แต่ละ Request “หนัก” แค่ไหน
1. ที่จังหวะ Peak Load (ช่วงที่แย่งกันลงทะเบียนเรียน) จะมีผู้ใช้ทั้งหมดประมาณกี่คน
กรณีระบบลงทะเบียนเรียน เราสามารถหาข้อมูลนี้ได้จากสำนักงานทะเบียน ว่าปัจจุบันมีนิสิตนักศึกษาทั้งหมดกี่คน
สมมติว่ามหาวิทยาลัยมีนิสิตนักศึกษาป.ตรีทั้งหมด 25,000 คน เราอาจจะกะง่ายๆว่า จะมี Peak Load อยู่ที่ประมาณ 80% ของป.ตรี เพราะอีก 20% อาจจะไม่ต้องลงเรียนวิชาที่มีคนแย่งกันมาก หรือไม่แคร์ว่าจะลงได้หรือไม่ได้ (ตัด ป.โท กับป.เอก ออก เพราะไม่ต้องแย่งกันลงเหมือนป.ตรี)
เราก็จะได้ข้อมูลคร่าวๆว่า 80% x 25,000 = 20,000 คน
เอาเข้าจริง ระบบนี้อาจจะต้องใช้งานต่อไปอีกสักสิบปี จำนวนผู้ใช้ก็คงจะโตขึ้นตามอัตราส่วน ถ้าคุยกับทางมหาวิทยาลัย เราอาจจะเดาได้ว่าตัวเลขประมาณการณ์จริงๆน่าจะสักประมาณเท่าไร เช่น จากสถิติย้อนหลัง เราอาจจะพอเดาได้ว่าปริมาณนิสิตจะเพิ่มขึ้นปีละประมาณ 5% ถ้าเราจะออกแบบระบบให้รองรับคนได้ใน 10 ปีข้างหน้า เราก็ต้องเอาข้อมูลนี้มาคำนวนด้วย หรือหากเราทราบว่ามหาวิทยาลัยอาจจะมีการเปิดสาขาใหม่ในอีกปีสองปีข้างหน้า จำนวนนิสิตอาจจะพรุ่งพรวดขึ้นมาเลยก็ได้
ส่วนตัวเลข 80% ถ้าเรารู้พฤติกรรมของผู้ใช้มากขึ้น ผ่านการสุ่มตัวอย่างสัมภาษณ์ หรือมีข้อมูลสถิติการใช้งานจากระบบเก่า ก็จะทำให้เรากะได้แม่นยำขึ้น
อย่างไรก็ตาม อย่าลืมว่าการประเมินนี้เป็นแบบ"คร่าวๆ" ยังไงเราก็ไม่สามารถทำให้เป๊ะได้ จึงไม่ควรใช้เวลากับมันเยอะเกินไป
ในทางปฏิบัติ ระบบที่ทำส่วนใหญ่จะเป็นระบบใหม่ที่ยังไม่มีคนเคยใช้ เราอาจจะต้องเดินไปถามฝ่ายการตลาดว่าขนาดตลาดโดยรวมของผู้ใช้มีประมาณกี่คน ทีมตั้งเป้าว่าจะได้ส่วนแบ่งทางการตลาดกี่เปอร์เซ็นต์ พฤติกรรมการใช้งานน่าจะเป็นยังไง มีการเข้าเว็บไซต์เราบ่อยแค่ไหน แล้วค่อยเอาตัวเลขมากะ Peak Load เอา ถ้าฝ่ายการตลาดตอบพวกนี้ไม่ได้ อันนี้แปลว่า Product ไม่ได้ทำ Market Research มาดีพอ แนะนำว่าให้ไล่บี้ต่อนิดนึงให้เค้าทำการบ้านให้ดี ไม่งั้นระบบนี้อาจได้ทำฟรีไม่มีคนใช้ หรือไม่ก็ทำแล้วรับ Scale ได้คนละเรื่องกับจำนวนจริง
สำหรับระบบจำลองของเรานี้ เราสรุปเอาง่ายๆละกันว่ามหาวิทยาลัยคงไม่ได้รับนิสิตนักศึกษาเพิ่ม Peak Load ก็น่าจะอยู่ที่ 20,000 คนโดยประมาณ
2. ผู้ใช้แต่ละคนจะส่ง Request เท่าไร
ข้อนี้เราก็ต้องมาดู User Interaction ว่าหากผู้ใช้คนหนึ่งลงทะเบียนเข้าเรียน จะต้องมีการโต้ตอบอะไรกับระบบบ้าง
| ขั้นที่ | ผู้ใช้ | ระบบ |
|---|---|---|
| 1 | เข้าสู่ระบบ | ตรวจสอบ Username และ Password ว่าถูกต้อง |
| 2 | คลิ๊กที่ลิ้งก์ “ลงทะเบียนเรียน” | ส่งหน้าเว็บเพจสำหรับลงทะเบียนเรียนให้กับผู้ใช้ |
| 3 | ผู้ใช้กรอกรหัสวิชาทุกวิชา และกด Submit | ตรวจสอบแต่ละวิชากับฐานข้อมูลว่าเต็มแล้วหรือยัง ถ้ายัง ให้บันทึกการลงทะเบียนวิชานั้นๆ แต่หากเต็มแล้ว ก็ไม่ทำการลงทะเบียนให้ หลังจากตรวจสอบครบทุกวิชา ให้แสดงผลรหัสวิชาที่ลงทะเบียนเรียนสำเร็จ และไม่สำเร็จกลับไปยังผู้ใช้ |
| 4 | ผู้ใช้เลือกจบการลงทะเบียน หรือส่งรหัสวิชาอื่นๆที่อยากลงทะเบียนเพิ่มเติม | ย้อนกลับไปข้อ 3 หรือจบการทำงาน |
สมมติคร่าวๆว่า ผู้ใช้ส่วนใหญ่จะลงทะเบียนไม่ทัน ต้องทำ ขั้นที่ 4 ซ้ำอีก 2 ครั้ง โดยเฉลี่ย ผู้ใช้จะต้องส่ง Request มาโดยเฉลี่ยประมาณ 6 ครั้ง (4 ขั้น + 2 ครั้ง) กว่าจะจบการลงทะเบียน
ตรงนี้การวาง Interaction Flow จะมีผลมาก เช่น เราอยากจะมี Typeahead ให้กับการกรอกหมายเลขวิชา ก็จะมีปริมาณ Request เพิ่มอีกเยอะมาก ซึ่งอาจจะทำให้ระบบที่ออกแบบเปลี่ยนไปอีกเยอะเลย คนที่จะต้องมานั่งทำ Trade-off กับเราก็จะเป็นฝั่ง UX Designer
เรื่องจำนวน Request นี่่ก็จะมีกรณีแปลกๆ เช่น มีคนเปิดบอทไว้ใช้ลงทะเบียนเรียน ซึ่งถ้าเราไม่ทำการ Throttling อาจจะทำให้จำนวน Request พุ่งขึ้นทะลุยอดได้ง่ายๆ อันนี้เพื่อความง่าย จะขอตัดกรณีแปลกๆพวกนี้ไป
ด้วยข้อมูลนี้ ในช่วงเวลาหนึ่งนาที เราจะมี Request เข้ามา 20,000 คน x 6 ครั้ง = 120,000 Request ในหนึ่งนาที เฉลี่ยๆแล้วระบบต้องรับโหลดได้ประมาณ 2,000 Request/second
ถ้าถามว่า 2,000 Request/second นี่มันเยอะรึเปล่า อันนี้ตอบยาก เพราะเรายังมีข้อที่ 3 อยู่
3. แต่ละ Request “หนัก” แค่ไหน
อย่างหนึ่งที่มองข้ามไม่ได้ คือแต่ละ Request มีความ"หนัก" ต่อแต่ละส่วนของระบบไม่เท่ากัน เช่น Request แต่ละชนิดมีการประมวลผลบนเซอร์เวอร์มากน้อยไม่เท่ากัน หรือมีการเรียก Read/Write Database ไม่เท่ากัน
ในกรณีนี้ เรามาวิเคราะห์ส่วนของ Database Read/Write กัน
ขั้นที่ 1 นั้นจะต้องมีการอ่านข้อมูล(Read)จาก Database เพื่อตรวจสอบว่ารหัสผ่านถูกต้องหนึ่งครั้ง
ขั้นที่ 2 เซอร์เวอร์สามารถส่งหน้าเว็บเพจกลับได้เลย ถ้าหน้านี้ไม่ได้มีข้อมูลแบบ Dynamic เราก็ไม่ต้องอ่านข้อมูลจาก Database จึงถือว่า"เบา" มาก
ขั้นที่ 3 จะมีทั้งการ Read และ Write ใน Database หลายครั้ง (สำหรับแต่ละวิชา) โดยต้อง Read มาดูว่าเต็มรึเปล่าก่อน ถ้าเฉลี่ยแล้วนิสิตลงทะเบียนกันคนละประมาณ 6 วิชา จะต้องมีการอ่าน Database 6 ครั้ง (เว้นแต่เราจะทำการ Optimize Query) และทำการ Write ประมาณ 1-6 ครั้ง
ขั้นที่ 4 จะมีจำนวนการ Read ตามปริมาณการลงทะเบียนที่ไม่สำเร็จ สมมติว่าให้เฉลี่ยอยู่ที่ 2 ครั้ง แต่ขั้นตอนนี้จะถูกทำซ้ำรวม 3 ครั้ง
จะเห็นได้ว่า ส่วนที่หนักที่สุดต่อ Database คือขั้นตอนที่ 3 หากใช้วิธีการคำนวนคร่าวๆแบบด้านบน เราก็จะสามารถคำนวนจำนวน Read/Write per second โดยเฉลี่ยออกมาคร่าวๆได้ ซึ่งหากเราพบว่าต้องมีการติดต่อ Database เยอะ อันนี้ก็จะเป็นสัญญาณให้ระวังว่าส่วนที่ล่มก่อน จะเป็น Database ไม่ใช่ Server
เมื่อรวมข้อมูลทั้งหมดมา เราจะกะได้คร่าวๆว่าในแต่ละ Session จะมีการ
| ขั้นที่ | DB Read | DB Write |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 0 | 0 |
| 3 | 6 | <=6 |
| 4 | 2*3 | <=6 |
เฉลี่ย จะมี Read อยู่ที่ประมาณ 13 ครั้ง , Write 6 ครั้ง (จะ Write แค่เฉพาะวิชาที่ลงทะเบียนเรียนได้) สำหรับผู้ใช้ 1 คน ตลอด Session
ถ้าให้ผู้ใช้ทำการลงทะเบียนทั้งหมดเสร็จใน 1 นาที Read = 13 ครั้งต่อคน * 20,000 คน / 60 วินาที = 4,333 ครั้ง/วินาที Write = 6 ครั้งต่อคน * 20,000 คน / 60 วินาที = 2,000 ครั้ง/วินาที
อันนี้ผมตอบได้เลยว่าเยอะ ถ้าเขียนอ่านลง Database ตรงๆทั้งหมด โอกาสล่มค่อนข้างชัวร์
ในทางปฏิบัติจริง ถ้าทำออกแบบ Database Table, ทำ Indexing, และเขียน SQL Query ดีๆ น่าจะลดปริมาณ Read/Write ลงไปได้เยอะมาก แต่หัวข้อนี้อยู่นอกสโคปของบทความ ขอไว้พูดถึงในโอกาสหน้านะครับ
Bottleneck
ในระบบลงทะเบียนเรียน ระบบจะต้องจัดการปริมาณในช่วงลงทะเบียน (Peak Load) ได้ โดยไม่ล่ม
โดยปกติแล้ว ระบบที่รับ Request ไม่ไหวจนล่มเพราะทรัพยากรไม่เพียงพอ มักจะล่มอยู่ที่ทรัพยากรเหล่านี้
- CPU
- Memory
- Disk I/O (Read/Write)
- Network
เราเรียกทรัพยากรเหล่านี้ว่าคอขวด (Bottleneck) ตัวอย่างเช่น ในระบบที่มี Request มากๆ แต่ละ Request ไม่มีการอ่านข้อมูลจาก Database ระบบมักจะมีคอขวดอยู่ที่ CPU หรือ RAM ของเซอร์เวอร์ แต่หากมีการอ่านเขียนข้อมูลจาก Database แล้ว Thread/Process ต้องรอผล Bottleneck ก็น่าจะไปอยู่ที่ I/O แทน
ในขณะที่ระบบที่ต้องมีการอัพเดตข้อมูลต่อเนื่องกันเร็วๆ อย่างระบบลงทะเบียนของเรา หรือระบบจองตั๋ว อันนี้คอขวดมักจะอยู่ที่ Disk I/O หรือ RAM ของ Database
กรณีที่เราสามารถสร้างระบบจำลองขึ้นมาทำ Load Test ได้ อันนี้จะหาค่าเหล่านี้ได้ใกล้เคียงมากที่สุด โดยเราสามารถทดลองยิง Request ใส่เข้าไปในระบบ แล้วเพิ่มจำนวนของ Request ขึ้นเรื่อยๆ จนถึงจุดที่ระบบไม่สามารถรับได้ (หรือรับได้แต่ Latency สูงเกิน) ณ จุดนั้น เราก็เข้าไปเช็คดูว่า Resource ตัวไหนที่หมดก่อน
ซึ่งถ้าลองทำ Load Test แล้วระบบสามารถรับจำนวนที่เราคำนวนก่อนหน้านี้ได้ เราก็สามารถปรับลดทรัพยากรของเครื่องให้อยู่ในเกณฑ์ที่เหมาะสมได้
หรือหากมีระบบเก่าอยู่แล้ว เราอาจจะใส่ Monitoring Tool เพื่อดูพฤติกรรมของระบบตอนที่มีคนใช้เยอะๆ ว่าทรัพยากรไหนมีแนวโน้มที่จะเป็น Bottleneck
กรณีที่เราไม่มีระบบอยู่ (หรือมีแต่ระบบจริงที่ทำสองวิธีข้างบนไม่ได้) อันนี้ก็ต้องนั่งเทียนเอา อาจจะต้องไปเช็ค Benchmark ของเทคโนโลยีที่เราใช้แล้วกะๆเอา ซึ่งจากประสบการณ์ ส่วนใหญ่จะหาข้อมูลที่ใช้จริงได้ยากมาก เช่น บทความใน NGINX request/second ก็มีตัวแปรเรื่อง Hardware, Request size, SSL เข้ามาเกี่ยวข้องอยู่ดี
แม้่ Hardware, Server, Request size, Technology Stack ตรงกันเป๊ะๆ แต่ผู้ใช้ดันมาจากคนละ Region ทำให้ Network Latency ไม่เท่ากัน จำนวน Concurrent Request ที่ค้างอยู่ในระบบก็จะไม่เท่ากันด้วย ทำให้กะได้ค่อนข้างยาก
โดยส่วนตัว ผมแนะนำว่าให้เผื่อไว้ดีกว่าขาด ถ้าใช้ Cloud ก็ออกแบบให้มัน Scale ขึ้นลงได้ง่ายๆ ใส่ Monitoring Tool เอาไว้ แล้วพอเห็นว่าจำนวนผู้ใช้จริงประมาณเท่าไร แล้วค่อยมาปรับจำนวนเอา
หรืออีกเทคนิคนึงที่เห็นก็คือการเอาระบบใหม่เข้าไปใส่เป็น Shadow ของระบบเก่า เพื่อให้รับโหลดจริงๆ (แต่ผลลัพธ์ที่ผู้ใช้ได้ยังคงอยู่ในระบบเก่าทั้งหมด) แล้วมา Monitor ดูว่าไหวรึเปล่า
เทคนิคการออกแบบระบบให้รับ Request ได้มากขึ้น
หลังจากได้ข้อมูลทั้งหมดแล้ว เราจะมาออกแบบระบบกัน !! (ในที่สุด…) โดยเราจะปรับปรุงจาก Three-Tier Architecture ที่เรามีไว้ตอนแรก
1. Scaling Vertically vs Horizontally
จริงๆวิธีการแก้ปัญหาที่ง่ายที่สุด คือการอัดทรัพยากรเข้าไปเพิ่ม
ถ้า CPU ไม่พอ ก็เพิ่ม CPU ถ้า Memory ไม่พอ ก็เพิ่ม Memory เข้าไป
โดยสมัยก่อน การเพิ่มแบบนี้จะเป็นการอัพเกรดเครื่อง หรือย้ายไปเครื่องใหม่ที่มีเสป็คแรงขึ้น วิธีนี้เราอาจมองได้ว่าเป็นการทำให้เครื่องใหญ่ขึ้น ศัพท์เฉพาะหรูๆของการ Scale แบบนี้คือ Vertical Scaling (ขยายแนวตั้ง)
การเพิ่มแบบแนวตั้งนี้มีปัญหาหลายอย่าง ได้แก่
- เราจะไม่สามารถขยายเครื่องใหญ่ขึ้นได้ตลอดไป หลังจากขยายขนาดเครื่องไปเรื่อยๆ ราคาจะแพงขึ้นในแบบ Exponential คุณไม่มีทางเอาเครื่องๆเดียวรับคำสั่งค้นหา Google ทั้งโลกได้ (แม้จะสร้างได้ในทางทฤษฏี แต่ในทางปฏิบัติ เครื่องน่าจะใหญ่มากจนไม่สามารถก่อสร้างได้ในราคาที่เราสามารถจ่ายได้)
- มี Downtime ในการอัพเกรด ณ จุดหนึ่งที่เมนบอร์ดใส่แรมครบแล้ว เราก็ต้องอัพเกรดโดยการเปลี่ยนไปยังเครื่องใหม่ โดยการเปลี่ยนไปยังเครื่องใหม่นี้จะต้องมี Downtime (ช่วงเวลาที่ต้องปิดปรับปรุงระบบ) ซึ่งอาจจะกินเวลาเป็นวัน
- เราต้องมีทรัพยากรเกินความจำเป็นตลอด เช่นในระบบลงทะเบียนเรียนข้างต้น เราต้องวางระบบให้รองรับ 2,000 Request/วินาที ซึ่งปริมาณ Load ขนาดนี้จะเกิดขึ้นแค่เทอมละครั้ง แต่เราต้องมีเครื่องที่รับปริมาณ Request ที่สูงมากๆอยู่ตลอดเวลา ส่วนเวลาอื่นๆ เครื่องก็ทำงานโดยไม่ได้ใช้ประสิทธิภาพเต็มที่
ดังนั้น การออกแบบสมัยใหม่เลยเน้นไปที่การเพิ่มแบบ Horizontally หรือแนวนอน
การเพิ่มแบบแนวนอนคือการใส่เซอร์เวอร์ใหม่เพิ่มเข้าไป โดยไม่ต้องแตะเซอร์เวอร์เก่า เวลามี Request จากฝั่งผู้ใช้ พวก Request นี้ก็จะโดนกระจายไปตามเซอร์เวอร์ต่างๆ
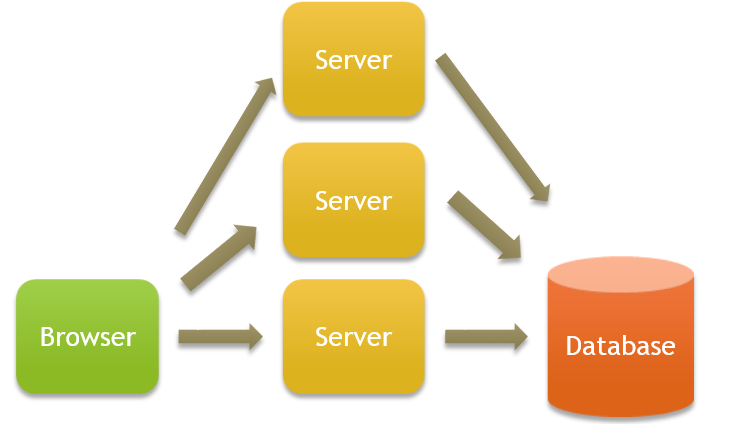
หากออกแบบมาดี การ Scale Horizontally นั้นจะช่วยลดปัญหาข้อที่ 1 และ 2 ได้
ส่วนข้อ 3 ถ้าหากใช้ระบบ Cloud ที่สามารถปรับปริมาณทรัพยากรที่ใช้แบบอัตโนมัติได้ เช่น ปกติเราอาจจะรันระบบด้วยเซอร์เวอร์แค่สองตัว แต่พอเข้าสู่ช่วงลงทะเบียนเรียน เราจะเพิ่มปริมาณเซอร์เวอร์เป็นสิบตัวในวันแรกๆของการลงทะเบียน ทำให้ลดค่าใช้จ่ายได้
2. Read Replica
ตัวอย่างการ Scale ข้างต้นนั้นอยู่ในส่วนของเซอร์เวอร์ แต่ถ้าส่วนที่เป็นคอขวดจริงๆคือส่วนของ Disk I/O ของ Database ล่ะ?
ปัญหานี้มีสามารถแก้ได้หลายทาง วิธีแรกที่จะคุยกันคือการทำ Read Replica
วิธีนี้อาจจะคล้ายๆกับ Scaling Horizontally โดยเราจะทำการก็อบข้อมูลของ Database ทั้งหมด แยกมาไว้ในอีก Database หนึ่ง แล้วให้คำสั่งอ่าน (Read) วิ่งไป Database นี้แทน
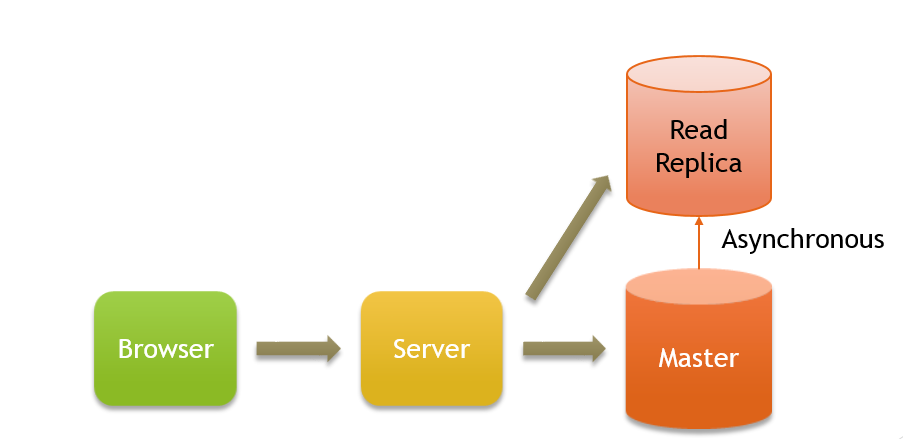
หากมีการเขียน เราก็จะส่งไปที่ Database หลัก (เราจะเรียกกันว่า Master) แล้วตัว Master ก็จะทำการก็อบข้อมูลไปยัง Read Replica แบบ Asynchronous
วิธีนี้ดูผิวเผินอาจจะช่วยใช้แก้ปัญหาได้ แต่จริงๆแล้วจะมี Trade-off ที่สำคัญมากๆ เพราะการก็อบข้อมูลเป็นแบบ Asynchronous ที่เราควบคุมไม่ได้ว่าจะเสร็จเมื่อไร
ยกตัวอย่างเช่น หากเรามีวิชาที่คนแย่งกันลงทะเบียนมากๆ ณ จุดหนึ่ง Replica อาจจะมีคนลงทะเบียนที่ 80 จาก 100 คน (80/100)
ทันใดนั้น มีคนลงทะเบียนเข้ามาพรวดเดียวอีก 20 คน ทำให้ข้อมูลที่ตัว Master นั้นเต็มแล้ว (100/100) แต่ยังไม่ได้ทำการก็อบข้อมูลไปยัง Replica
ณ จุดนี้ หากมีคนลงทะเบียนเพิ่ม เวลาเซอร์เวอร์อ่านข้อมูลจาก Read Replica ซึ่งยังเป็น (80/100) เซอร์เวอร์ก็จะคิดว่าเรายังลงทะเบียนได้อยู่ ทำให้เกิดการลงทะเบียนเกิน (101/100)
บางคนอาจจะได้ไอเดียว่า ถ้า Asynchronous มันมีปัญหา ก็ทำแบบ Synchronous สิ คือทุกครั้งที่ Write ให้ทำการอัพเดต Replica ให้เสร็จก่อน เวลาเกิดการ Read ครั้งถัดไป เราจะได้มั่นใจว่าการ Read ทุกครั้งได้ข้อมูลที่ตรงกัน (Consistency)
วิธีนี้แก้ปัญหาได้ แต่ค่าใช้จ่ายที่จะตามมาก็คือการเขียนจะต้องใช้เวลานานขึ้น (เพราะต้องเขียนทั้งสอง Database) และมีความซับซ้อนมากขึ้นเพราะต้องจัดการกรณีที่การเขียนลง Replica ไม่สำเร็จ (แต่ดันเขียนลง Master ไปแล้ว) พอจะ Scale ให้มีจำนวน Read Replica มากขึ้น เพื่อรับโหลดเพิ่ม ปัญหานี้จะทวีความรุนแรงมากขึ้นเรื่อยๆ ทำให้จัดการยากมาก
ดังนั้น หากใครคิดจะใช้ Read Replica ให้พิจารณาให้ดีว่าเรายอมรับกรณีที่การอ่านข้อมูลหลังจากการเขียนช้าไปนิดนึงได้ไหม ซึ่งถ้ารับ Trade-off ตรงนี้ได้ วิธีนี้ก็จะสะดวกมากทีเดียว เพราะ Database ส่วนใหญ่นั้นมักจะมีฟีเจอร์นี้ให้อยู่แล้ว
3. Caching
อีกหนึ่งทางเลือกคือการทำ Caching ข้อมูลที่ต้องใช้บ่อยๆ ไว้ใน Memory แทนที่จะเป็น Disk
ตัวอย่างเช่น หากเราค้นพบว่า Bottleneck คือ Database ของข้อมูลที่เราต้องใช้บ่อยมากในขั้นที่ 4 นั่นคือ จำนวนคนที่ลงทะเบียนเรียนไปแล้ว ในแต่ละรายวิชา
| รหัสวิชา | จำนวนคนที่ลงทะเบียนไปแล้ว | รับทั้งหมด |
|---|---|---|
| 2110332 | 30 | 120 |
| 3800250 | 50 | 50 |
| 2300150 | 55 | 60 |
ทางเลือกหนึ่งคือเราอาจเก็บข้อมูลส่วนนี้แยกไว้ใน Memory ของเซอร์เวอร์ (กรณีที่เรามั่นใจว่ามีเซอร์เวอร์แค่ตัวเดียว)
กรณีที่เรามีเซอร์เวอร์หลายตัว การ Synchornize ค่าตารางนี้ในแต่ละเซอร์เวอร์จะวุ่นวายมาก วิธีที่เหมาะสมกว่าคือเก็บไว้ใน In-Memory Database (Redis, Memcached) ในกรณีที่เรามี Server หลายตัว
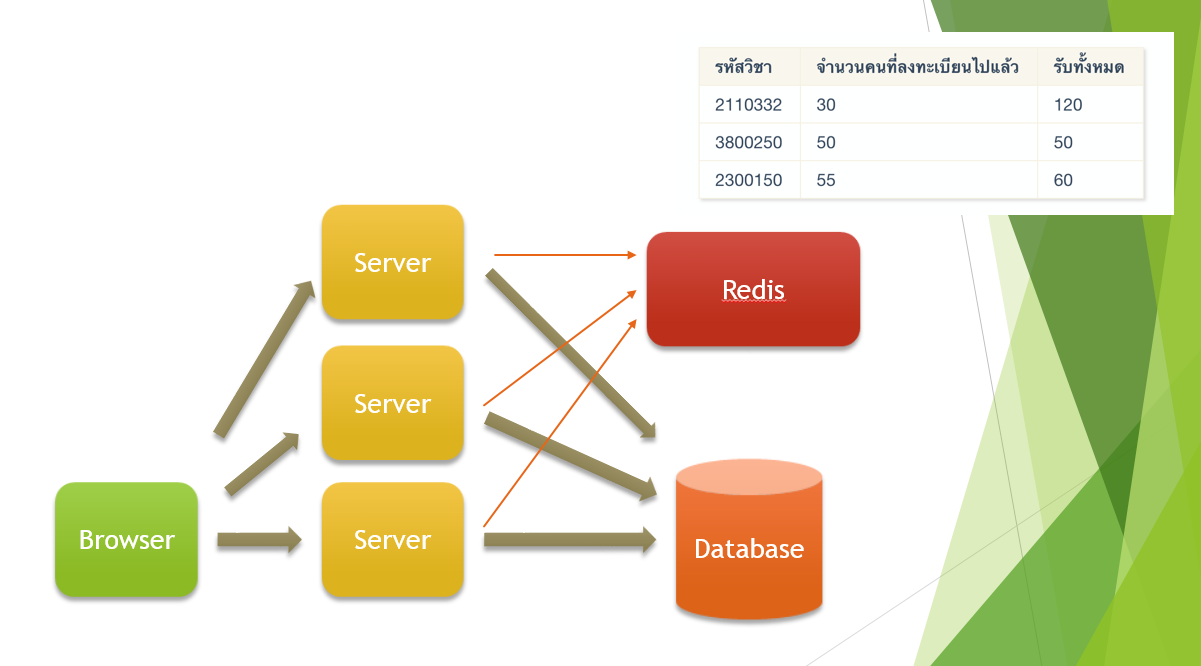
วิธีนี้ทำให้เราสามารถอ่านข้อมูลได้อย่างรวดเร็วกว่า แทนที่จะต้องติดต่อ Database ทุกครั้งว่ายังลงทะเบียนเพิ่มได้หรือเปล่า เราก็สามารถตรวจจากข้อมูลใน Memory ได้เลย ซึ่งจะเร็วกว่าเป็นพันเท่า (การดึงข้อมูลใน Memory ใช้เวลาประมาณ 100 ns ในขณะท่ี Disk Read อยู่ที่ 150,000 ns)
ความซับซ้อนที่เพิ่มขึ้นมา คือเวลาเราจะต้องเก็บข้อมูลอยู่สองที่ หากเกิดอะไรขึ้นระหว่างการเขียนข้อมูล อาจจะทำให้ข้อมูล Inconsistent ได้ อันนี้ตัวโปรแกรมจะต้องจัดการให้ดี ว่าในกรณีที่เกิด Exception หรือ Error หลังจากเขียนข้อมูลลงไปใน Cache แล้ว เราจะทำการ Restore ค่ากลับอย่างไร
4. Data Partitioning
หากเรามองปัญหาในอีกมุมหนึ่ง เราสามารถออกแบบข้อมูลของ Database ให้กระจายไปอยู่หลายๆเครื่องได้ เช่น
- ข้อมูลวิชาบังคับของแต่ละภาค
- ข้อมูลวิชาเลือก (Free Elective) ของทุกภาควิชา
เราอาจจะค้นพบว่า วิชาที่เกิดการแย่งลงมากๆ (มีการ Read/Write) เยอะๆ คือพวกวิชา Free Elective ซึ่งมีแค่ประมาณ 10% ของวิชาทั้งหมด
เราอาจจะแยกวิชาพวกนี้เข้าไปเก็บใน Database หนึ่งโดยเฉพาะ แล้วให้เซอร์เวอร์ติดต่อ Database นี้แยกต่างหาก เวลาต้องการเช็คการลงทะเบียนเรียนเกี่ยวกับ Free Elect
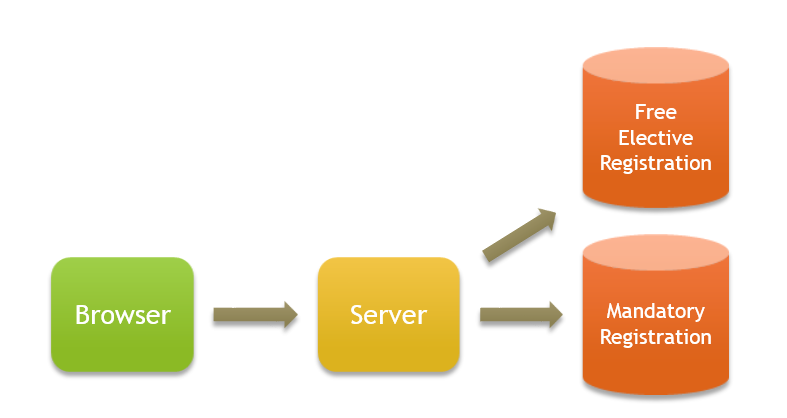
วิธีนี้เป็นการกระจาย Load ในระบบด้วยความรู้ใน Domain ของระบบ ตัวอย่างอื่นๆก็เช่น เฟสบุ้ครู้ว่าเรามักจะค้นคนที่อยู่ประเทศเดียวกัน เฟสบุ้คก็อาจจะกระจายการเก็บข้อมูลให้คนในประเทศเดียวกันเก็บข้อมูลใน Database เดียวกัน (หรืออยู่ใน Data center เดียวกัน) ก็จะได้ดึงข้อมูลได้เร็ว
กรณีที่เราไม่รู้อะไรเลย (ไม่รู้ว่าวิชาไหนคนแย่งกันมากๆ) ก็อาจจะทำการสุ่มกระจายข้อมูลเท่าๆกันลงบนทุก Database
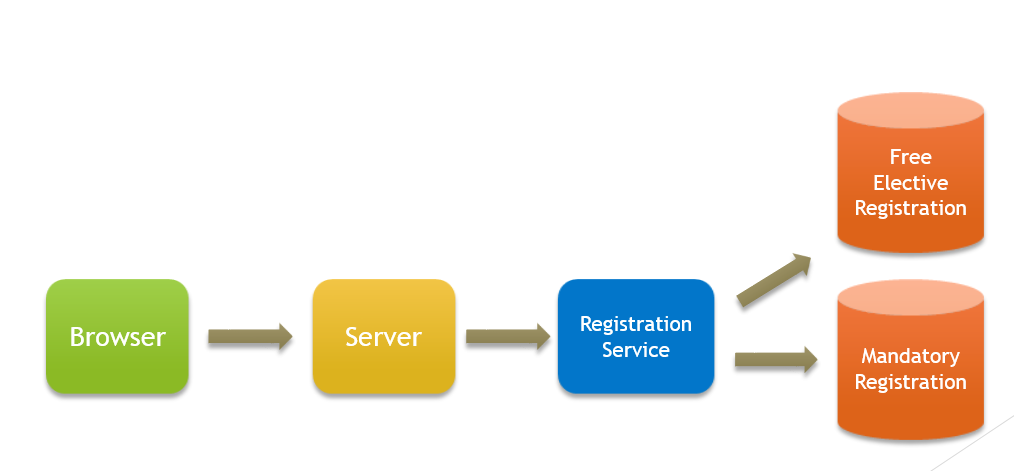
ในทางปฏิบัติ วิธีนี้มีปัญหาตรงที่โค้ดในฝั่งเซอร์เวอร์นั้นจะต้องมาคอยรับรู้ว่าข้อมูลมีการกระจายยังไง และถ้าเราต้องการดึงข้อมูลการลงทะเบียนเรียนของผู้ใช้คนหนึ่งออกมา ก็ต้องดึงจากสองข้อมูล ถ้าคนดูแลโค้ดพวกนี้ทั้งหมดเป็นทีมเดียวกันก็อาจจะไม่ใช่ปัญหามาก แต่หากมีหลายทีม การปล่อยให้ Implementation Details (วิธีการเก็บข้อมูล) หลุดไปในฝั่ง Server นั้นถือว่าเป็น Bad practice ที่จะทำให้ทีมทำงานได้ช้า เพราะต้องมารอกัน
ดังนั้น เราควรจะแยกการลงทะเบียนเรียนออกมาเป็น Service ของตัวเองเลย ฝั่ง Server ก็จะได้ไม่ต้องรับรู้ว่าข้อมูลถูกเก็บยังไง แค่ไปเรียก API เพื่อทำการอ่าน/เขียนข้อมูลแทน
สรุป
เราเริ่มต้นด้วยโจทย์ว่าจะทำอย่างไรให้ระบบลงทะเบียนเรียนไม่ล่มเวลามีคนใช้เยอะๆ
จากโจทย์ เราพยายามหาข้อมูล เพื่อประมาณจำนวน Peak Load แบบคร่าวๆ การรู้ Peak Load ตัวนี้จะทำให้เรากะปริมาณ Hardware เพื่อให้ทรัพยากรที่เป็นคอขวด (Bottleneck) มีเพียงพอ
ในการออกแบบระบบ หาก Bottleneck อยู่ที่เซอร์เวอร์ เราสามารถใช้วิธี Scale แบบ Horizontal (ใส่เครื่องเพิ่ม) ได้ง่ายๆ
แต่หากคอขวดอยู่ที่ฝั่ง Database การเพิ่มจำนวน Database แบบตรงๆจะไม่ทำให้ประสิทธิภาพเพิ่มตามจำนวน เพราะการเขียนทุกครั้ง เราจะต้องเขียนลงบน Database ทุกตัวเพื่อให้ข้อมูลตรงกัน ทำให้ไม่สามารถรองรับปริมาณ Request ได้เพิ่มไปจากเดิม
ดังนั้น เราจึงต้องใช้วิธีอื่นๆในฝั่ง Database เช่น Read Replica, Caching, Data partitioning
ในบทความนี้ก็จะอธิบายเทคนิคแต่ละแบบคร่าวๆที่ใช้กันบ่อยและไม่ซับซ้อนมาก ในทางปฏิบัติ หากระบบมีขนาดใหญ่มากๆ อาจจะต้องใช้เทคนิคอื่นๆที่มี Multi-master เช่น Two-Phase commit, Quorum หรือ Partitioning แบบที่ซับซ้อนกว่านี้