เขียนเทสต์อย่างไรให้ไม่บาป (ฉบับที่ 2 System Integration Tests/End-to-End Tests)
จากประสบการณ์ส่วนตัว End-to-End(E2E) Tests เป็นตัวที่สร้างความปวดหัวให้กับผมอันดับที่หนึ่งเลย รองลงมาก็ System Integration Tests ตอนเขียนบทความนี้ฉบับแรก เลยตัดสินใจแยกเทสต์สองประเภทนี้ออกมาเขียนแยกออกมา จะได้ลงรายละเอียดได้
บทความนี้ก็เหมือนบทความที่แล้วครับ คือทำผิดมาเยอะ จนพอจะสรุปข้อผิดพลาดที่เคยทำไว้มาแชร์กัน ผู้อ่านจะได้หลบเลี่ยงกันได้
ควรอ่านอะไรมาก่อน
ถ้าใครที่เขียน Unit/Component/Integration/E2E Test เป็นประจำอยู่แล้ว ข้ามส่วนนี้ไปได้เลยครับ
แต่ถ้าใครที่ไม่ได้เขียนเทสต์เยอะๆ ผมแนะนำให้อ่านสองบทความนี้ก่อนครับ
บทความนี้จะต่อขยายเนื้อหาจากสองบทความแรก เพราะปัญหาของ Unit/Component Tests ส่วนใหญ่ก็จะเกิดกับ System Integration/E2E Tests เหมือนกัน (ยกเว้นเรื่อง Mock)
นิยามของ System Integration Tests/End-to-End Tests
ก่อนอื่นมาทำความเข้าใจกันก่อนว่าเวลาผมพูดคำว่า System Integration Tests/End-to-End Tests ที่ผมพูดนี่มันหมายถึงอะไรกันแน่
เริ่มจากคำว่า Integration Test ก่อน (ไม่มีคำว่า System) นี่เป็นหนึ่งในคำที่สับสนที่สุดในวงการเลย ไม่เชื่อให้ไปถามคนในแต่ละทีมทีละคนดูว่าหมายถึงอะไร จะได้คำตอบที่แตกต่างกันมาก
- บางคนก็บอกว่าถ้าไม่เป็น Unit Test ก็เป็น Integration Test หมด (คือรวม Component Testing ด้วย)
- บางคนก็จะหมายถึงการเอา Component หลายๆอันมาต่อกันเป็น Service แล้วลองเทสต์ทั้ง Service ดู
- บางคนก็จะหมายถึงเอา Service มารวมกันให้ครบเป็นระบบที่ทำงานได้ แล้วลองทดสอบดูว่ามันทำงานด้วยกันได้
ถ้าไปค้นวิกิดู จะได้นิยามว่า
Integration testing is the phase in software testing in which individual software modules are combined and tested as a group – Wikipedia
ซึ่งปัญหาของคำนี้ มันอยู่ที่คำว่า Module นี่แหละครับ เราจะมองว่า Class แต่ละคลาสเป็นหนึ่ง Module ก็ได้ หรือจะมองว่าคลาสหลายๆคลาสรวมกันเป็น หนึ่ง Module (เหมือน Package ใน Java) หรือมองว่าทุกๆอย่างรวมกันในหนึ่งเซอร์วิซเป็นหนึ่ง Module ก็ได้เหมือนกัน
นิยามไหนถูก ผมว่าไม่สำคัญ สำคัญว่าคนในทีม (หรือในบริษัท) ควรจะมีนิยามเดียวกัน ว่าเวลาเราพูดว่า Integration Tests เนี่ย เรากำลังพูดถึงการ Integrate กันในระดับไหน
เพื่อเลี่ยงความสับสน ผมจะใช้คำว่า System Integration Tests (SIT) แทน ซึ่งในที่นี้ ผมหมายถึงการนำเซอร์วิซทุกอันมารันบนเซอร์เวอร์จริง (ไม่มีการ Mock เหมือนกรณี Unit/Component Tests) ให้มีการเรียกใช้งานกันระหว่างเซอร์วิซจริงระหว่างการเทสต์
ถ้าระบบของเราเป็น Web Service การทดสอบนี้คือการเรียกใช้ผ่าน HTTP, RPC หรือ Protocol ที่จะต้องถูกใช้งานจริงๆบน Production
หากระบบของเรามี User Interface (UI) เช่น มีหน้าเว็บไซต์ แล้วเวลาดึงข้อมูลก็จะดึงผ่าน API Call เราจะทดสอบด้วยการใช้เฟรมเวิร์คที่สามารถ Simulate การคลิกตามตำแหน่งต่างๆของเว็บไซต์เหมือนผู้ใช้งานใช้เว็บนั้นอยู่จริงๆ เรียกว่า UI Driver (เช่น Selenium) กรณีนี้ผมขอเรียกว่า End-to-End Test (E2E)
E2E ก็เป็นอีกชื่อนึงที่คลุมเครือ บางที่ก็อาจจะเรียกชื่ออื่นนะครับ
ถ้าสรุปเป็นภาพ หน้าตาจะประมาณนี้ครับ
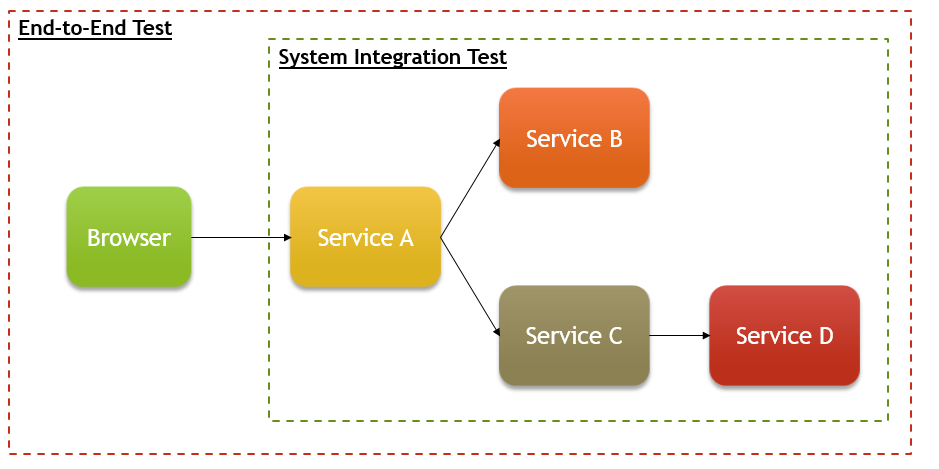
ตามนิยามนี้ เราจะเห็นได้ว่า ข้อแตกต่างของการทดสอบทั้งสองแบบนี้ คือตัวนึงเทสต์ในระดับ UI, ส่วนอีกตัวคือ Service API
ส่วนที่คล้ายกันคือ การทดสอบทั้งสองแบบจะใช้ระบบจริง รันบนเซอร์เวอร์จริง เรียกใช้ Dependency จริง (ซึ่งอาจจะมี Dependency ข้างหลังบ้างนอีก เช่น Service C เรียก D ต่อ)
ส่วนที่คล้ายกันนี้ทำให้เกิดปัญหาที่คล้ายๆกันครับ เช่น
- ความเปราะ (ฺBrittleness) แก้อะไรนิดหน่อยก็พัง ยิ่ง E2E เนี่ย บางทีแก้ชื่อคลาสทีนึงก็พังแล้ว
- อาการรันแล้วพังบ้างไม่พังบ้าง (Flakiness) ซึ่งสาเหตุอาจจะมาจากเทสต์โค้ดที่เขียนไม่ดีเอง หรือ Dependency ที่ไม่เสถียร
- แกะยากมากว่าพังจากตรงไหน (Failure Isolation) เพราะเป็นได้ตั้งแต่โค้ดของเราไปจนถึง Dependencies (ซึ่งอาจเป็น Dependency ของ Dependency อีกทีที่มีปัญหา)
- ความช้า (Slowness) รันทีนานมาก ต้องบางโปรเจ็คต้องรันกันข้ามคืน พอพังทีก็ไม่แน่ใจว่ามาจาก Commit ไหนเพราะทั้งวันมีเป็นสิบ Commit
ทุกโปรเจ็คที่ผมทำมา ถ้าเขียน SIT/E2E Tests จะเจอปัญหานี้หมด มากน้อยไม่เหมือนกัน
หลังจากเราเข้าใจนิยามของสองคำนี้แล้ว ไปดูกันต่อครับ ว่าผมทำอะไรผิดมาบ้าง ถึงเจอปัญหาพวกนี้
1. Dependencies ไม่เสถียร
เวลารัน SIT/E2E เราจะต้องมีการเรียกใช้งาน Dependency ที่ถูก Deploy บนเซอร์เวอร์จริง (Service B, C, D ในภาพข้างบน) ดังนั้น ทีมที่ทำ SIT/E2E จะต้องมี Pre-Production Stage
Pre-Production Stage ที่ดี ควรจะเหมือนระบบจริงทุกอย่าง ต่างกันแค่ปริมาณเซอร์เวอร์ที่รันเพราะต้องรับ Load ที่ต่างกัน
ถ้าโชคดี ทีมเราเป็นคนคุมทุก Dependency ที่มีหมด เราก็จะสามารถจัดการจังหวะการรันเทสต์ หรือ Deploy ให้ไม่ชนกันได้ ซึ่งการันตีได้ว่าระหว่างที่รันเทสต์นั้น Dependency ทุกตัวที่เราใช้จะเสถียรหมด
แต่ในทางปฏิบัติ โปรดักต์ที่ใหญ่ๆ แต่ละ Dependency มักจะถูกดูแลโดยคนละทีม ทำให้ SIT/E2E ที่เคยรันผ่านตามปกติ อยู่ดีๆก็พังขึ้นมา เพราะ Dependency เกิดไม่เสถียรระหว่างที่รันพอดี เกิดอาการ Flakiness ขึ้นมา
ตัวอย่างกรณีที่ทำให้เกิดการไม่เสถียรก็เช่น
- Dependency มีการ Deploy ในขณะที่เรากำลังรันเทสต์อยู่
- Dependency พึ่งลงเวอร์ชั่นใหม่ที่มีบั๊ก หรือไม่ Backward-Compatible
- มีการรันเทสต์อื่นๆบน Dependency นั้นๆในจังหวะเดียวกันพอดี กรณีนี้อาจจะมีการเขียนข้อมูลทับซ้อนกันเอง หรือปริมาณ Load เกินกว่าที่ Dependency จะรับได้
ปัญหาแรก ถ้าฝั่ง Dependency ถูกออกแบบมาให้เป็น High Availability อยู่แล้ว ระหว่างที่ Deploy ก็จะไม่มี Downtime ทำให้ตัดปัญหาไปได้ ถ้าคุมเรื่อง Backward Compatibility กันดีๆ ก็จะไม่มีปัญหาอะไร
ปัญหาที่ 2 อันนี้ต้องมีการตกลงกันระหว่างทีมกันให้ดี ว่า Pre-Production Stage ตัวนี้จะต้องถูกใช้ในการทำ SIT/E2E ดังนั้น ที่ Stage นี้ จะต้องมีแต่การรันโค้ดที่ผ่านการทดสอบมาในระดับหนึ่งแล้ว เช็ค Backward-Compatibility แล้วค่อยส่งขึ้นมา ไม่ใช่ถูกใช้เป็นด่านแรกในการทดสอบ
ส่วนปัญหาที่ 3 อันนี้อาจจะแก้ได้ด้วยการตกลงว่าจะไม่รันเทสต์อย่างอื่นในระบบนี้ เก็บไว้สำหรับใช้ SIT/E2E อย่างเดียว
วิธีการแก้ปัญหาข้างบนทั้งหมด อยู่บนสมมติฐานว่าทุกทีมตกลงกันได้ว่าจะมี Pre-Production Stage ที่เสถียรให้สำหรับการทำ SIT/E2E
แต่หากทุกทีมตกลงกันไม่ได้ล่ะ
- บางทีมอาจจะบอกว่าตนมี Legacy System ที่ไม่มี Pre-Production Stage (แล้วแม่งเทสต์กันยังไง?)
- ฝั่ง Management อาจจะมองว่าประโยชน์ในการสร้าง Pre-Production Stage ไม่คุ้มกับเวลาที่ต้องใช้
- ต้องรออีกสัก 6 เดือน กว่าจะสั่งเซอร์เวอร์ใหม่มาทำ Pro-Production stage ได้
“อยู่กับสิ่งที่มี ไม่ใช่สิ่งที่ฝัน” – เพลงพี่บอย
ชีวิตจริงมันโหดร้าย กรณีที่เราแก้ไขที่ต้นเหตุไม่ได้ อาจจะต้องยอมลดเป้าหมายเราลงมาหน่อย ทางเลือกที่เป็นไปได้ก็มีอยู่สองทาง
- กรณีที่ Test Fail ครั้งแรก รอสัก 2-3 วิ แล้วรันเทสต์ใหม่อีกรอบ หากพังซ้ำ ถึงค่อยใส่ Test ให้เป็น Fail (อันนี้ก็ต้องแงะแต่ละ Testing Framework มาดู ว่าให้ใส่โค้ด Decorator เข้าไปได้ไหม) ถ้าครั้งที่สองผ่าน ก็ให้ถือว่าผ่าน
- Mock Dependency นั้นซะ อย่างน้อยก็ยังดีกว่าไม่มี Test เลย
ที่จริงผมเคยเห็นที่โปรเจ็คทดสอบ SIT/E2E กับ Production ของ Dependency ด้วย แต่ผมแนะนำว่าอย่าเสี่ยงเลย ถ้าจำเป็นต้องทำถึงขนาดนั้นก็ยอม Mock ดีกว่า
2. ไม่คุมเงื่อนไขตั้งต้นให้ดี (Incorrect Start Condition)
เทสต์ทุกเทสต์ เวลาเริ่มต้นจะต้องมี Pre-condition ของมันอยู่ เช่น มี User อยู่ในระบบให้ใช้งานแล้ว หรือ มีข้อมูลตั้งต้นที่เอาไว้ทดสอบการลบข้อมูล
พวก Pre-condition เหล่านี้ควรจะถูกเซ็ตตั้งแต่เริ่มต้นเทสต์ (เช่น @BeforeTest, @BeforeClass ใน Java, beforeEach() ใน Jamine)
หลังจากตั้งค่าเสร็จ คนส่วนใหญ่มักจะลืมทำการเคลียร์ค่า เช่นกรณีที่เทสต์รันไม่ผ่าน ลบข้อมูลไม่ได้ ข้อมูลที่เตรียมไว้ลบก็ควรจะถูกเคลียร์ออกด้วย
คราวนี้พอเราลืมเคลียร์ค่าให้เรียบร้อย ค่าพวกนี้ก็จะค้างอยู่ในระบบ โชคดีหน่อยเทสต์ก็พังทันที รู้เลย แต่ถ้าโชคร้าย ค่าพวกนี้อาจจะทำให้เทสต์พังบ้าง ไม่พังบ้าง (Flakiness)
เนื่องจากโปรแกรมเมอร์เป็นมนุษย์ และมนุษย์สร้างความผิดพลาดได้ ผมจะเน้นเช็ค Pre-condition ให้ละเอียดมากๆตลอด เพราะอาจจะมีมือใหม่ในทีมเขียนเทสต์แล้วลืมเคลียร์ค่าบางกรณี แล้วอยู่ดีๆค่านี้ก็มาทำให้เทสต์ผมพัง
หรืออีกกรณี เราอนุมานว่าเทสต์แต่ละตัวจะรันต่อเนื่องกัน บางคนก็เขียนเทสต์แรกให้สร้าง Record แล้วให้เทสต์ถัดไปลบ Record นั้น กรณีนี้เคยกล่าวไว้ในบทความที่แล้วว่าอันตรายมาก เพราะเทสต์แต่ละตัวอยู่คนละ Method กัน นอกจากจะต้องพึ่ง Side Effect กันแล้ว หากเทสต์ตัวนึงเฟล เทสต์อีกตัวนึงก็จะเฟลด้วย ทำให้หาสาเหตุยาก (Failure Isolation)
ดังนั้น เวลาเขียนเทสต์ พยายามอนุมานว่าเงื่อนไขตั้งต้นที่เรามีจะเป็นอะไรก็ได้ และตรวจสอบเงื่อนไขตั้งต้นให้ดีก่อนรันเทสต์
ถ้าหากมีอะไรผิดปกติ (เช่น User ไม่มี) ให้รีบ Fail Test ให้เร็วที่สุด เวลาไล่โค้ดจะได้ไม่ต้องไล่เยอะเพราะมันไปพังตอนบรรทัดท้ายๆ
ถ้ามั่นใจ เราอาจจะทำการล้างค่าเก่าอยู่แล้วที่เราต้องล้างทิ้งแล้วสร้างใหม่
ส่วนเวลาเทสต์จบ ก็ควรเคลียร์ค่าที่เทสต์สร้างไว้ให้ครบเหมือนกัน
บางคนกลัวว่าเช็คเยอะจะทำให้เทสต์ช้า แต่เชื่อผมเถอะว่าเทสต์ช้ามันแก้ทีหลังได้ แต่ถ้าเทสต์ไม่เสถียรนี่แก้ยากมากๆ
3. เทสต์ชนกัน (Tests Interfere with each Other)
หนึ่งในปัญหาที่ผมเคยเจอตอนเขียน SIT/E2E Test แล้วให้ Run แบบ Parallel คือเทสต์ชนกัน
เช่น ผมสร้างข้อมูลใหม่ 4 Records แต่พอตรวจดู กลับกลายมี 5 Records เพราะอีกเทสต์ (ที่กำลังรันพร้อมกัน) สร้างอีก Record มาไว้ทดสอบการลบ
เทคนิคในการแก้มีหลายแบบ แล้วแต่กรณี เช่น
- เวลาสร้าง Record ให้ใส่ Prefix + Random Value ทิ้งไว้ และเวลาตรวจสอบ ก็ให้ Filter เฉพาะตัวที่ Prefix ของ Record ตรงกัน
- ให้เทสต์แต่ละกลุ่มมี User ของตัวเอง โดยต้องมั้่นใจว่าแต่ละกลุ่มไม่มี Test ที่รันแล้วชนกัน
- การันตีให้แต่ละเทสต์ที่รันพร้อมกันมี User คนละตัวตลอด เช่น แยก User Pool ออกมา เวลาเทสต์แต่ละตัวเริ่มรัน ก็ให้ขอ User ใหม่มาจาก Pool นี้ ตัว Pool จะคอยคุมไม่ให้เทสต์ได้ User ตัวเดียวกันไปรันพร้อมกัน พอรันเทสต์เสร็จก็จะต้องคืน User กลับเข้า Pool (วิธีนี้ซับซ้อนกว่า แต่เซฟกว่า ก็ต้องเรื่อง Trade-off เอา)
4. ไม่แยกโค้ดที่ต้องใช้บ่อยๆออกมา (No Reusable Components)
ปกติ Test Code นี่คล้ายๆเป็นลูกเมียน้อย ไม่ค่อยมีคนแคร์เรื่องการดูแลรักษากันมาก
บางทีมที่โหดๆ คือก็อบเทสต์โค้ดจากไฟล์ข้างๆแล้วมานั่งแก้ ทำแบบนี้ซ้ำๆกัน พอทำไปสัก 20-30 ไฟล์ จะมี Logic ส่วนที่ซ้ำกันเยอะมาก
ยกตัวอย่าง E2E Testing ส่วนที่ซ้ำกันมากๆคือการเลือก UI Element เพื่ออ่านค่า หรือเซ็ตค่าต่างๆ ซึ่งจะต้องมีการใส่ Wait และเช็ค Condition ให้ดีว่า Element นั้นโผล่ขึ้นมาบนหน้าจอแล้ว ก่อนที่จะอ่านค่า
พอเวลาผ่านไป เทสต์จะแก้ไขยากมาก ตัวอย่างเช่น ถ้า UI Element นั้นเกิดเปลี่ยนชื่อขึ้นมา เราจะต้องไปตามแก้ในทุกไฟล์เลย Search Replace กันระงม
ถ้าไม่ได้เปลี่ยนชื่อ แต่เปลี่ยนชนิด (เช่น เปลี่ยนจาก Dropdown เป็น Typeahead) อันนี้ยิ่งอ้วกหนักกว่าเดิม
กรณีของ Web UI มีเทคนิคที่เรียกว่า Page Object คืคือการแยกให้ตัว Test รู้แค่ Business Logic เท่านั้น แต่ไม่รู้ว่าเกิดอะไรขึ้นในการดึงข้อมูลจาก UI
|
|
กรณีนี้ ถ้าเกิดตัว Business Logic ไม่เปลี่ยน (get/count users) เราก็สามารถไปแก้ที่ Page Object ที่เดียว เทสต์ที่เรียก Method พวกนี้ก็จะไม่ได้รับผลกระทบ ช่วยลดความเปราะ (Brittleness) ลงได้
5. ไม่รอ Asynchornous Operation ให้ดี
ใครที่เคยเขียนพวก UI Driver อย่าง Selenium น่าจะคุ้นเคยกับปัญหาเรื่องการรอ (Wait) เป็นอย่างดี โดยเฉพาะพวก Single Page Application
ตัวอย่างเช่น เวลาคลิ๊กที่ปุ่ม Create จะทำการเปลี่ยนหน้าและแสดงฟอร์มในการสร้าง Record ใหม่ พอใส่ค่าในฟอร์มเสร็จและกด Submit
ถ้าเราเขียนโค้ดว่า
|
|
ถ้าไม่ทำการ Wait ให้ดี โค้ดนี้อาจจะมีปัญหา ได้ในช่วงระหว่าง createNewRecord() กับ fillForm()
เพราะการเปลี่ยนหน้าจอเพื่อแสดงฟอร์มนั้น อาจจะใช้เวลา 30 ms แต่ตัว UI Driver อาจจะทำงานเร็วกว่า ทำให้จังหวะที่พยายามจะ fillForm() นั้น ตัวฟอร์มอาจจะยังโหลดขึ้นมาไม่เสร็จ
ปัญหาของการทำงานกับ UI พวกนี้ เกิดมาจากที่ UI ทำงานแบบ Asynchronous
หลังจากเรากดปุ่น Create ไป เราไม่สามารถการันตีได้ว่าฟอร์มจะโผล่ขึ้นมาเมื่อไร ซึ่งทำให้เทสต์เกิดอาการรันผ่านบ้างไม่ผ่านบ้าง (Flakiness)
เฟรมเวิร์คต่างๆก็จะมีวิธีแก้ไขต่างกันไป แต่ที่ผมเห็นบ่อยก็จะใช้วิธีการ Wait ตาม Condition ต่างๆ เพื่อให้การทำงานส่งผลเหมือน Synchronous เช่น
|
|
อันนี้ขอเน้นนิดนึง ว่าให้ Wait ตาม Condition อย่าไปใส่ Wait เป็นเวลาตายตัว เช่น ใส่ Thread.sleep(100) เฉยๆ เพราะวันดีคืนดีเกิดเครื่องช้าเกินจำนวนที่ Sleep ไว้ หรือเราอาจจะมีการเปลี่ยนโค้ดให้ดึงข้อมูลจาก Backend ทุกครั้งที่กด Create ทำให้เปลี่ยนหน้าช้าลง เทสต์ก็จะพังโดยมิได้นัดหมาย (Brittleness)
จะให้ดีกว่า ทุก Method ใน Page Object เราจะทำการ Wait() รอจน UI เปลี่ยนก่อน ถึงจะจบการทำงาน วิธีนี้จะทำให้เทสต์โค้ดอ่านง่ายขึ้น ไม่ต้องใส่ Wait มาคั่นหลายที่
|
|
ประโยชน์ของการดูแลโค้ดให้ดี อ่านง่าย คือทำให้การดีบั๊กง่ายขึ้น (ช่วยบรรเทาปัญหา Failure Isolation)
เรื่องจะใส่ AndWait ไว้หลัง Method ดีรึเปล่า ก็แล้วแต่ทีมตกลงกันนะครับ ที่ผมใส่ไว้เพื่อให้อ่านแล้วเคลียร์ ในทางปฏิบัติ หากเรามีโค้ดเก่าที่ไม่ได้ Wait อัตโนมัติ แล้วเราแก้โค้ดให้ Wait หมดรวดเดียวไม่ได้ ก็ใส่ไว้เพื่อให้เพื่อนร่วมทีมเข้าใจชัดเจน ว่าอันไหน Wait อันไหน ไม่ Wait
ส่วนคนที่ทำ API Test ถ้าตัว API ไม่ได้การันตีว่าเป็น Synchronous อาจจะต้องทำการรอและดึงข้อมูลซ้ำในทำนองเดียวกัน เช่น หากตัว Database ที่ใช้มีพฤติกรรมแนว Eventual Consistency (คือหลังจากแก้ข้อมูลแล้ว พออ่านใหม่ อาจจะยังได้ค่าเก่าแป๊บนึง ต้องรอสักพักค่าถึงจะเปลี่ยน)
6. ไม่รีบแก้ Flaky Tests ตั้งแต่เนิ่นๆ
ผมบอกไปข้างต้นว่า SIT/E2E มักจะมีปัญหาหลักๆสี่อย่าง คือ Brittleness, Flakiness, Failure Isolation, และ Slowness
ในบรรดาสี่อย่างนี้ ตัวที่ผมกลัวมากที่สุดคือ Flakiness เพราะมัน Reproduce ยาก และหาต้นเหตุยากโคตรๆ
Flakiness อาจจะมาจากเรื่องของ Timing, Side effect, Starting condition, หรือ Unstable dependency ก็ได้
เมื่อใดก็ตามที่เทสต์อยู่ดีๆก็พังบ้างไม่พังบ้าง มันเป็นสัญญาณว่าควรหยุดทุกอย่าง แล้วหาสาเหตุซะ
หากไม่ปิดสาเหตุตั้งแต่เนิ่นๆ พอจำนวนเทสต์เยอะแล้วหาเจอยากมากๆ เช่นในกรณีของ Side Effect หากมีเทสต์สักร้อยตัว จะหายากมากว่า Side Effect มาจากตัวไหน
หนึ่งในสิ่งที่ช่วยในการดีบั๊กเทสต์ในระดับนี้ คือ Log
หากจะ Debug ข้าม Dependency ก็ต้องมี Universal ID ที่เอาไว้ใช้ไล่ Log ได้ข้าม Dependency ได้ ว่าเกิดอะไรขึ้น ตั้งแต่ระบบต้นน้ำไปยังปลายน้ำ
อีกอย่างก็ที่เฟรมเวิร์คบางอันมีให้ก็คือการ Screenshot จังหวะที่เทสต์ล่ม อันนี้ก็จะทำให้ดีบั้กได้ง่ายขึ้นว่ามันเกิดข้อผิดพลาดอะไรขึ้น
7. เขียนเทสต์มากไป (Too Many Tests)
SIT/E2E เป็นเทสต์ที่ดูแลยาก ปัญหาเยอะ
พอมีเยอะๆแล้วนอกจากเสียเวลาแล้วยังใช้เวลารันนานด้วย
ถ้าถึงจุดที่ต้องรันหลายช.ม. อันนี้จะเริ่มบั่นทอน Productivity ของทีม เพราะ Feedback ที่ได้จาก Test จะช้ามาก พังทีไม่รู้ว่ามาจาก Commit ไหน คนในทีมจะต้องมีวินัยว่ารันเทสต์ที่เกี่ยวข้องและมีโอกาสพังให้ผ่านหมด ก่อนที่จะ Push ขึ้นไปรันบน CI Server ซึ่งควบคุมกันได้ยากมาก
ส่วนตัว ผมจะให้เทสต์ระดับนี้มีแค่ประมาณ 10% ของเทสต์ทั้งหมด ซึ่งจะทำอย่างนั้นได้ ทีมก็จะต้องมีข้อตกลงที่ชัดเจน ว่าจะเขียน SIT/E2E ในกรณีไหนบ้าง
บางทีมอาจจะตกลงว่าให้เขียนเฉพาะ Happy Flow (คือไม่ดักกรณี Error) บางทีมอาจจะตกลงว่าให้เขียน Sad Flow ที่ผู้ใช้เจอบ่อยด้วย
แล้วพวกกรณีอื่นๆล่ะ?
อันนี้ต้องผลักภาระลงไปเทสต์ระดับล่างๆ (Unit/Component) ทำแทน เพราะเทสต์พวกนี้เบา และรันได้เร็วกว่ามาก
ท้ายที่สุดแล้ว ลองย้อนกลับมาคิดดูครับ ว่าเราเขียนเทสต์ไปเพื่ออะไร และเทสต์ที่เรากำลังจะเขียนเพิ่ม มีคุณค่าพอที่จะใช้เวลา Maintain มันไหม
ตรงนี้ประสบการณ์จะช่วยได้ เพราะพอเห็นเยอะๆ ก็จะพอเดาได้ว่าเวลาที่ใช้ดูแลมันเยอะแค่ไหน และโอกาสป้องกันไม่ให้บั๊กหลุดไปได้มากแค่ไหน ทำให้ตัดสินใจได้ง่ายขึ้น
สรุป
เราเริ่มต้นด้วยนิยามของ SIT และ E2E Testing เพื่อให้เข้าใจตรงกัน ว่ามันมีลักษณะเด่นอะไร และปัญหาหลักๆของมันมีอะไรบ้าง
หลังจากนั้น เราก็มาเจาะลึกถึงข้อผิดพลาด 7 แบบ ซึ่งทำให้เกิดปัญหาเหล่านี้ขึ้น พร้อมวิธีแก้ไข (หรือบรรเทา)
ด้วย Tool กับ Practice ที่เรามีอยู่ปัจจุบันนี้ ส่วนตัวผมคิดว่า SIT/E2E เป็นเทสต์ที่ต่อให้วางแผนดีแค่ไหนก็มีปัญหา แค่มีปัญหาน้อยลงหน่อยเท่านั้นเอง
หากทีมมีการทำ Code Review ก็ควรจะเคร่งส่วนนี้กันให้มาก ไม่งั้นทีมอาจจะเข้าไปอยู่ในอาการเทสต์ท่วมหัว เอาตัวไม่รอด เพราะรันช้า พังบ้างไม่พังบ้าง แถมแก้ทีนึงก็แดงเถือกวินาศสันตะโรหมด