จะสเกลระบบหลักล้านด้วย Cache ต้องพิจารณาอะไรบ้าง

แคช(Cache)เป็นหนึ่งในตัวเลือกที่ถูกใช้บ่อยมากในการสเกลระบบให้สามารถรับโหลดได้เยอะๆ ถ้าใครไปสัมภาษณ์งานแล้วเจอคำถามว่าระบบมีคนใช้หลักล้าน และเป็นการอ่านข้อมูลเป็นหลัก (Read-intensive) ตอบได้เลยว่าใช้แคช แต่รายละเอียดของคำตอบว่าจะใช้ยังไง ต้องพิจารณาเรื่องไหนบ้าง เราจะมาคุยกันในบทความนี้ครับ
ชี้แจงก่อนว่า เราจะคุยกันในมุมของการออกแบบระบบ (System Design) ซึ่งจะเป็นการใช้แคชในระดับของ Backend services เพราะแนวคิดของแคชนั้นถูกใช้ในทุกระดับ ยกตัวอย่างเช่น
- ฮาร์ดแวร์ในเครื่องคอมพิวเตอร์ (ใครซื้อคอมอาจจะเห็นเสป็คของ L1/L2 Cache ของ CPU)
- แอพพลิเคชั่นที่เราใช้ (เว็บบราวเซอร์ทุกตัวมีแคช)
- ผู้ให้บริการอินเตอร์เน็ตมีการเก็บแคชของเว็บไซต์ที่ถูกเข้าถึงบ่อย หรือ Record ใน DNS
- Content Delivery Network (เช่น CloudFlare, Akamai)
- Backend services เก็บข้อมูลไว้เองใน RAM แทนที่จะดึงข้อมูลจากฐานข้อมูล (Database) หรือระบบอื่นๆ
- Distributed Cache เช่น Redis หรือ Memcached
เพื่อไม่ให้สับสน เวลาเราพูดถึงแคชในบทความนี้ ให้นึกถึงตัวอย่าง 5 กับ 6 นะครับ
ถึงแม้การใช้แคชจะตอบโจทย์ได้บ่อยมาก แต่ก่อนที่จะใส่เข้าไปในระบบ มีเรื่องที่ต้องพิจารณาค่อนข้างมาก มาดูกันครับ
ทำไมถึงใช้แคช
ตามที่เกริ่นไปขั้นต้น แคชนั้นเหมาะสมการกรณีที่ระบบมีอการอ่านข้อมูลเป็นหลัก ถ้าระบบที่คุณพัฒนาอยู่เริ่มมีการทำงานช้า แล้วพอนั่งวิเคราะห์อัตราส่วนของ Request แล้วพบว่าเป็น Read เกิน 80% ก็ควรพิจารณาใช้แคชได้แล้ว
แนวคิดของแคชคือการเก็บข้อมูลไว้ให้ใกล้ตัวที่สุด ลองพิจารณา 3-tier architecture ข้างล่างดูครับ
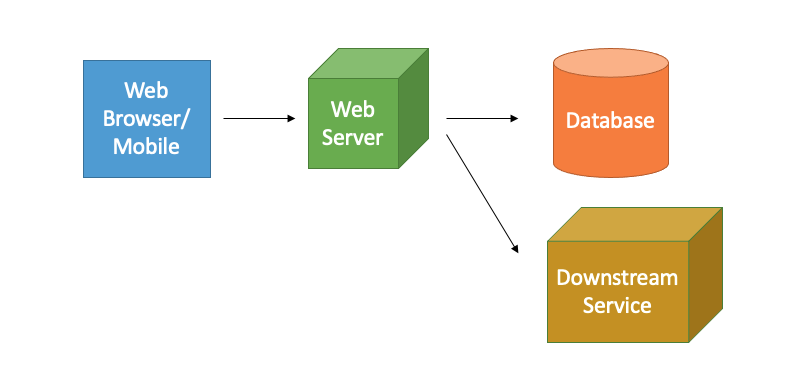
ตัวอย่าง 3-tier architecture ที่มี downstream service
ถ้าระบบมีการอ่านข้อมูลมากจนฐานข้อมูล(Database)ทำงานหนักเกินไป การใส่แคชเข้าไปในระบบจะลดการทำงานของฐานข้อมูล ทำให้ระบบรับโหลดได้ดีขึ้น (Improve scalability) และระบบตอบสนองได้เร็วกว่า(Reduced latency) เพราะแคชจะเก็บข้อมูลจากหน่วยความจำ (Memory หรือ RAM ที่เรารู้จักกัน) ซึ่งเร็วกว่าอ่านจากดิสก์มากๆ แถมยังไม่มี Network Call ด้วยหากเราเก็บแคชไว้ในเซอร์เวอร์
อีกกรณีคือระบบที่มีการคำนวนเยอะ เราสามารถคำนวนค่าพวกนี้และเก็บเอาไว้ในแคช ทำให้ไม่ต้องคำนวนใหม่หลายรอบ
นอกจากฝั่งฐานข้อมูล เราอาจจะใช้แคชในการเก็บข้อมูลที่ต้องเรียกใช้จากอีกระบบ (ในรูปข้างบนคือกล่อง Downstream service) แคชจะช่วยลดจำนวนรีเควสต์ที่เราต้องส่งไป ทำให้ระบบตอบสนองได้เร็วขึ้น และลดโหลดในระบบที่เรียกใช้
ไม่ว่าในกรณ๊ไหน ถ้าโหลดของระบบลดลง เราก็จะสามารถลดจำนวน(หรือขนาด)ของเครื่องที่เราต้องใช้ เราก็จะลดค่าใช้จ่ายไปโดยอัตโนมัติ (Reduced cost)
โดยสรุถป เราใชัแคชเพื่อบรรลุวัตถุประสงค์เหล่านี้ครับ
- ระบบสามารถรับโหลดได้ดีขึ้น (Imporved scalability)
- ระบบตอบสนองเร็วขึ้น (Reduced latency)
- ระบบที่เรียกใช้รับโหลดน้อยลง (Reduced load on downstream systems)
- ลดค่าใช้จ่าย (Reduced cost)
เรื่องที่ต้องพืจารณาก่อนใช้แคช
แคชจะดูมีประโยชน์มาก แต่ไม่มีอะไรได้มาฟรีๆครับ ก่อนที่จะใช้แคช เราต้องพิจารณาเรื่องพวกนี้ให้ดีก่อน
1. ขนาดของแคช
แคชมักจะถูกเก็บไว้ในหน่วยความจำ หน่วยความจำนั้นราคาแพงกว่าฮาร์ดดิสก์หลายเท่า ดังนั้น พื้นที่ของแคชจะมีขนาดเล็กกว่าฐานข้อมูลที่เราใช้มาก ทำให้เราไม่สามารถเก็บข้อมูลทุกอย่างลงในแคชได้หมด
ระบบที่ใช้แคชได้มีประสิทธิภาพ นอกจากจะมีการอ่านข้อมูลเป็นหลักแล้ว จะต้องมีการอ่านค่าเดิมซ้ำๆกันด้วย
สมมติว่าแคชสามารถเก็บข้อมูลได้แค่ 1 ชิ้น รอบแรก ผู้ใช้ขอข้อมูล A เราก็จะดึงจากฐานข้อมูลมาเก็บไว้ในแคชและส่งให้ผ้ใช้
พอรีเควสต์ถัดไปมา กลับขอข้อมูล B เราก็ต้องดึงจากฐานข้อมูลใหม่ เอา B ไปใส่ในแคชอีก
ถ้าเกิดดวงไม่ดีรีเควสต์ที่เข้ามาสลับไปสลับมาตลอดเป็น A ซัก 50% เป็น B อีก 50% ระบบนี้จะทำงานแย่กว่าเดิมอีก เพราะต้องมาคอยอัพเดตค่าแคชที่แทบไม่ได้ใช้เลย
แต่ถ้าระบบนี้มีรีเควสต์เป็น A อยู่ 99% แคชจะมีประโยชน์มาก เพราะใน 100 รีเควสต์ เราต้องดึงข้อมูลจากฐานข้อมูลแค่ 2 ครั้ง
ดังนั้น การเลือกขนาดของแคชมักจะต้องดูว่ารีเควสต์ดึงข้อมูลซ้ำๆกันแค่ไหน วิธีหนึ่งที่ใช้กันคือความถี่ของข้อมูลที่อ่านมาพล็อตเป็นกราฟ Histogram (เรียงลำดับจากที่ถูกอ่านถี่สุดไปต่ำสุด) หน้าตาควรจะออกมาประมาณนี้ครับ

ภาพ Longtail distribution จาก Wikipedia
ในภาพข้างบน ให้แกน X คือข้อมูลที่ถูกอ่าน ส่วนแกน Y คือจำนวนครั้งของการอ่านข้อมูลนั้นๆ
ข้อมูลที่อยู่ในส่วนเขียวคือส่วนที่สามารถเก็บไว้ในแคชได้ ซึ่งกะคร่าวๆว่าประมาณ 15% ของข้อมูลทั้งหมด (แกน X)
แต่แค่ 15% นี้ก็พอจะสามารถตอบกลับรีเควสต์ส่วนใหญ่ได้ทันทีโดยไม่ต้องดึงข้อมูลจากฐานข้อมูล เพราะมันคลุมพื้นที่สีเขียว ประมาณ 65% ของพื้นที่ทั้งหมด
เลข 65% นี้ศัพท์เทคนิคเรียกว่า Cache hit ratio ครับ
ถ้ากราฟตัวนี้อ้วนขึ้น (มีการอ่านค่าข้อมูลเดียวซ้ำๆน้อยลง) จะทำให้ส่วนสีเขียวลดลง เราจะมี Cache hit ratio ที่ต่ำลง เราก็ต้องขยายของแคชให้ใหญ่ขึ้น เพื่อที่จะได้มี Hit ratio กลับไปที่ที่ 65%
ถ้ากราฟแคบลง (มีการอ่านค่าข้อมูลเดียวซ้ำๆน้อยลง) เราจะมี Cache hit ratio ที่สูงขึ้น ถ้าเราพอใจกับ 65% เราอาจจะเลือกให้แคชมีชนาดเล็กลง เพื่อประหยัดค่าใช้
ถ้าหากขนาดของแคชไม่มากพอ สิ่งที่เกิดขึ้นคือข้อมูลที่ถูกอ่านไม่อยู่ในแคช ทำให้ต้องดึงข้อมูลใหม่ ซึ่งส่งผลให้ระบบช้าลง เพราะแคชไม่ได้ถูกใช้ แถมยังต้องเขียนข้อมูลใหม่ลงในแคชด้วย
อย่าลืมนะครับว่าแคชมีราคาแพง เราไม่สามารถทำแคชที่ใหญ่เท่ากับฐานข้อมูลได้ การมีข้อมูลการเข้าถึงข้อมูลแบบข้างบนจะทำให้เราปรับจูนขนาดของแคชได้เหมาะสมขึ้น
ตัวอย่างของระบบที่เหมาะกับการใช้แคช ได้แก่พวกเว็บไซต์ข่าวต่างๆ คนส่วนใหญ่ไม่ค่อยได้อ่านข่าวเก่า ข่าวที่มีการอ่านบ่อยๆก็มักจะเป็นข่าวในช่วงสัปดาห์ที่ผ่านมา
หรือเว็บไซต์อย่างทวิตเตอร์ที่มีการอ่านมากกว่าการอัพเดตและข้อความที่ถูกอ่านเยอะส่วนใหญ่ก็มักจะเป็นทวีตจากคนที่มีชื่อเสียง ก็น่าจะเหมาะสมกับการใช้แคช อย่างไรก็ตาม แคชจะต้องมีการอัพเดตกรณีที่มีคอมเม้นต์ใหม่ๆเข้ามา
2. ข้อมูลมีการเปลี่ยนแปลงบ่อยแค่ไหน
ข้อมูลที่มีการเปลี่ยนแปลงบ่อยนั้นไม่เหมาะสมการการใช้แคชครับ เพราะทุกครั้งที่มีการเปลี่ยนแปลง เราต้องอัพเดตทั้งข้อมูลต้นทาง(ในฐานข้อมูล)และข้อมูลในแคช ทำให้การอัพเดตนั้นช้าลง ถ้าจังหวะที่อัพเดตดันมีรีเควสต์อ่านเข้ามาพอดี ระบบก็อาจจะยังส่งค่าเก่าในแคชไปได้
สำหรับระบบบางประเภท การที่ข้อมูลที่เปลี่ยนแปลงมาช้าไปบ้างไม่ได้มีผลกระทบตัวอย่างกับผู้ใช้มาก เช่นโพสต์ในเฟสบุ้ค บางทีการอัพเดตโพสต์อาจจะไม่ขึ้นทันที อันนี้คนส่วนใหญ่ยอมรับได้ จุดนี้เป็น Trade-off ที่ผู้ออกแบบระบบสามารถเลือกได้
3. การเอาข้อมูลเก่าในแคชออก (Cache invalidation)
เนื่องจากแคชมีขนาดเล็กกว่าข้อมูลทั้งหมด พอเวลาผ่านไป แคชบางส่วนจะต้องถูกเอาออก
ตัวอย่างเช่น เรามีข้อมูลทั้งหมด 50 ชิ้น แคชใส่ได้แค่ 5 ชิ้น
เวลาผ่านไป เรามีข้อมูลเต็ม 5 ชิ้นอยู่ในแคช โดยถูกเก็บตามลำดับดังนี้
A, B, C, D, E
ณ จุดนี้ เรามีรีเควสต์ใหม่เข้ามาเพื่อดึงข้อมูล F
คำถามคือ เราเอาข้อมูลไหนออก แล้วเอา F เข้าไปใส่แทน เราจะเอาตัวไหนออก เอาตัวเก่าสุด A หรือตัวใหม่สุด E หรือไม่เอาออกเลย?
เรื่องนี้คือ Cache Invalidation strategy ครับ (บางคนก็เรียกว่า Replacement strategy, eviction policy) วิธีการให้เลือกหลายแบบ (อ่านเพิ่มเติม) วิธีที่นิยมกันมักจะเป็น Least Recently Used (LRU)
4. วิธีการอัพเดตข้อมูล
นอกจาก Invalidation เวลาที่แคชเต็มแล้ว เรายังต้องคำนึงด้วยว่าข้อมูลจะต้องมีการอัพเดตด้วย
แต่เดิม ถ้าเราเก็บข้อมูลไว้ที่เดียว เราก็แค่อัพเดตที่เดียวจบ พอมีแคชเข้ามา เราก็จะต้องอัพเดตทั้งสองที่ ทั้งฝั่งต้นทางของข้อมูล และในแคชด้วย
ถ้าเราเลือกจะเก็บแคชไว้ในหน่วยความจำของเซอร์เวอร์ (ไม่ได้แยกออกมา เช่นใช้ Redis หรือ Memchached) และเรามีเซอร์เวอร์หลายเครื่อง พอเวลามีการอัพเดต เราจะทำอย่างไรให้ค่านี้ในแคชของทุกเซอร์เวอร์ถูกเปลี่ยน (Cache coherance)
ถ้าระบบไม่ได้ต้องการ Consistency ที่สูง ยอมรับได้ว่าอาจจะส่งข้อมูลเก่าบ้างเป็นบางครั้ง เราอาจจะเลือกคือการติดค่า Time-to-live (TTL) ไว้ในแต่ละข้อมูล หากเวลาตัวนี้ยังผ่านไปไม่เกิน TTL ระบบจะส่งข้อมูลที่อยู่ในแคชกลับ หากเกิน ระบบจะเช็คข้อมูลจากต้นทางใหม่และทำการอัพเดตค่า วิธีนี้จะทำให้ระบบทำงานได้เร็วขึ้น แต่อาจจะมีการส่งค่าเก่ากลับไปบ้างเป็นบางครั้ง ถ้า TTL ยาวเกินไป
สรุป
การเลือกใช้แคชมีสิ่งต้องพิจารณาหลายอย่าง หากเราตัดสินใจเรื่องพวกนี้ไม่ดี นอกจากจะเสียเงิน เสียเวลาใส่แคชเข้าไปแล้ว อาจจะทำให้ระบบช้าลงหรือส่งค่าเก่ามาให้
ข้อมูลที่ใช้ประกอบการตัดสินใจคือ (1) รูปแบบการเข้าถึงข้อมูล (จำนวนความถี่ในการอ่านแต่ละข้อมูล) (2) การเปลี่ยนแปลงของข้อมูล
ซึ่งจะจำเป็นในการตัดสินใจว่าเราจะตั้งค่า (1) ขนาดของแคช, (2) การเลือก Invalidation strategy, (3) การอัพเดตค่าในแคช หรือ (4) การเซ็ตค่า TTL
ในทางปฏิบัติ ค่าพวกนี้มักจะมีการเปลี่ยนเรื่อยๆครับ สาเหตุเพราะตอนแรก เราอาจจะไม่ได้รู้รูปแบบการเข้าถึงข้อมูลที่แน่ชัด หรือรูปแบบนั้นอาจจะเปลี่ยนตามกาลเวลา ดังนั้น เราควรจะมีระบบ Monitoring ที่ดีเพื่อเก็บข้อมูลเหล่านี้ไว้สำหรับการปรับจูน
---
ติดตามบทความสำหรับโปรแกรมเมอร์ทั้งด้านได้ที่ Facebook page Not about code หรือ Twitter @notaboutcode บทความของเพจจะเน้นเนื้อหาที่นำไปใช้ได้กับชีวิตจริง แต่ไม่ยึดติดกับเทคโนโลยีหรือภาษา เช่น System Design, Continuous Delivery, Testing, Career, etc.
สำหรับท่านที่อยากสนับสนุนผู้เขียน รบกวนช่วยแชร์โพสต์ในเฟสบุ้คให้กับเพื่อนๆที่น่าจะสนใจหัวข้อพวกนี้ด้วยครับ